
API的理解与使用
(一)本章基础知识
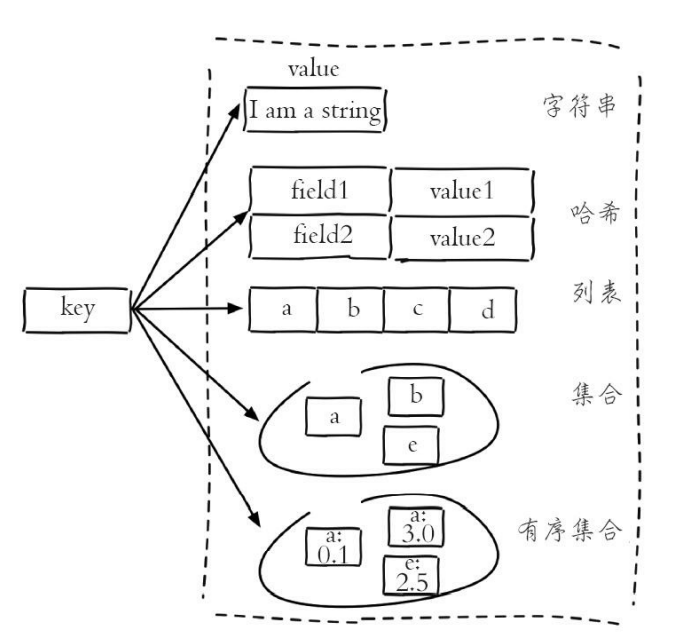
Redis数据类型
Redis总共有5中数据结构类型
- String - 字符串
- hash - 哈希
- list - 列表
- set - 集合
- zet - 有序集合
每种数据结构的底层都有多种实现,这样设计有两个好处:第一,可以改进内部编码,而对外的数据结构和命令没有影响;第二,多种内部编码实现可以在不同场景下发挥各自的优势,例如:ziplist比较节省内存,但在列表元素较多的情况下,性能会有所下降,此时,redis会根据配置选项将内部编码转换为linkedlist
可通过type key命令来查看存储的数据结构类型,可通过object encoding key命令来查询存储的内部编码
数据结构:
内部编码:
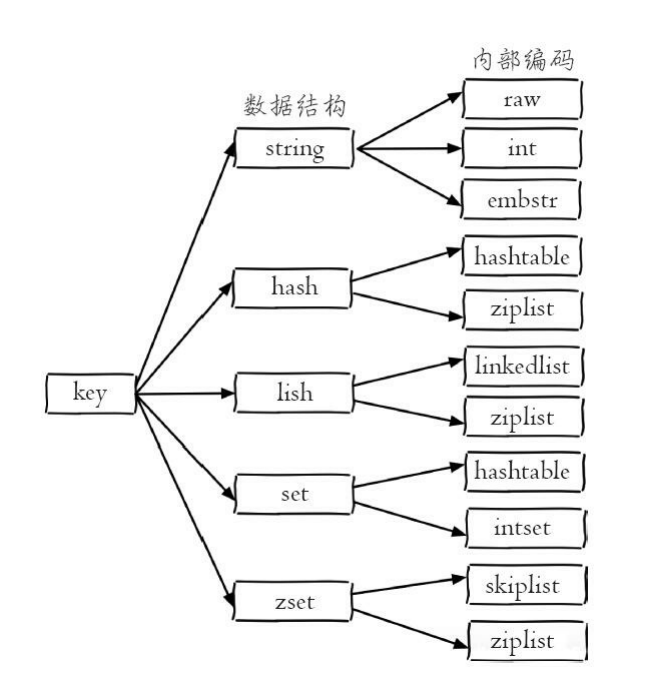
字符串类型内部编码:
redis会根据传入的类型和长度进行内部编码的选择
- int:8个字节的长整型
- embstr:小于等于39个字节的字符串
- raw:大于39个字节的字符串
哈希类型内部编码:
- ziplist:压缩列表,元素个数小与hash-max-ziplist-entries配置(默认512个),同时所有值都小于hash-max-ziplist-value配置(默认64字节)
- hashtable:哈希表,当条件不满足上述条件时,使用ziplist读写效率会下降,redis会将内部编码调整为hashtable,hashtable的读写时间复杂度为O(1)
列表内部编码:
一个列表最多可以存储2^32-1个元素
- ziplist:压缩列表,元素个数小与hash-max-ziplist-entries配置(默认512个),同时所有值都小于hash-max-ziplist-value配置(默认64字节)
- linkedlist:链表,当条件不满足上述条件时,redis会使用linkedlist作为列表内部编码实现
- quicklist:redis3.2版本提供了这种内部编码,结合了ziplist和linkedlist两者的优势
集合内部编码:
一个列表最多可以存储2^32-1个元素,集合中不允许有重复元素,并且集合中的元素是无序的,不能通过索引下标获取元素
- intset:整数集合,集合中的元素都是整数且元素个数小于set-maxintset-entries配置(默认512个)
- hashtable:哈希表,当条件不满足上述条件时,redis会使用hashtable作为集合内部编码实现
有序集合内部编码:
集合内顺序不能重复且可以排序
- ziplist:压缩列表,元素个数小与zset-max-ziplist-entries配置(默认128个),同时所有值都小于zset-max-ziplist-value配置(默认64字节)
- skiplist:跳跃表,当条件不满足上述条件时,redis会使用skiplist作为有序集合内部编码实现
集合中不能有重复成员,可以给每个成员设置一个分数作为排序的依据

Redis单线程架构
核心:I/O多路复用技术
为什么单线程还能这么快?
原因:
- 第一,纯内存访问
- 第二,非阻塞I/O
- 第三,单线程避免线程切换和竞态产生的消耗,简化数据结构及算法实现
(二)Redis使用场景
1. 基础场景
redis的set、get、expr(过期时间)等
SET命令
| 类型 | 命令 | 说明 | 备注 |
|---|---|---|---|
| 字符串 | set moss haha [ex 秒级过期时间/px 毫秒级过期时间] [nx/xx] | key为moss,value为haha,nx:键必须不存在,才可以设置成功,xx:键必须存在,才可以设置成功,用于更新 | set字符串,可存放json,xml,数字,二进制(不得超过512MB),setex等同于set+expire的组合,且该命令是原子的 |
| 字符串(批量) | mset moss1 hehe moss2 lolo | 用于批量设定键值对,减少redis网络交互开销 | |
| 哈希 | hset user:1 name tom | key为user:1,哈希的field为name,value为tom | 如果设置成功会返回1,反之会返回0 |
| 哈希(批量) | hmset user:1 name mike age 12 city tianjin | 是批量设置field-value |
GET命令
| 类型 | 命令 | 说明 | 备注 |
|---|---|---|---|
| 字符串 | get moss | 如果存在值或获取到value,若不存在值则获取到(nil) | |
| 字符串 | mget moss1 moss2 | 批量获取键值 | |
| 哈希 | hset user:1 name tom | key为user:1,哈希的field为name,value为tom | |
| 哈希(批量) | hmget user:1 name city | 是批量获取field-value |
2. 缓存
Redis作为客户端与数据库之间的缓存层,绝大部分请求的数据都是从Redis中获取。由于Redis具有支撑高
并发的特性,所以缓存通常能起到加速读写和降低后端压力的作用。
Key的命名,比较推荐的方式是使用“业务名:对象名:id:[属性]”作为键名,例如:如MySQL的数据库名为vs,用户表名为user,那么对应的键可以用”vs:user:1”,”vs:user:1:name”来表示,我们现在的手机银行token可以存储为业务名:token
伪代码:1
2
3
4
5
6
7
8
9
10
11
12
13UserInfo getUserInfo(long id){
userRedisKey = "user:info:" + id
value = redis.get(userRedisKey);
UserInfo userInfo;
if (value != null) {
userInfo = deserialize(value);
} else {
userInfo = mysql.get(id);
if (userInfo != null)
redis.setex(userRedisKey, 3600, serialize(userInfo));
}
return userInfo;
}
3. 计数
Redis可以实现快速计数、查询缓存的功能,例如微博的点赞和取消点赞功能
使用incr key、incrby key 2、decr key或decrby key 2的方法进行计数,此处需要考虑数据持久化的问题
4. 共享session
从单体架构转变到分布式架构通常都会遇到分布式session的问题,Redis可以帮助统一管理session,其实就是类似我们现在的前后端分离架构(token)
5. 限速
很多应用出于安全的考虑,会在每次进行登录时,让用户输入手机验证码,从而确定是否是用户本人。但是为了短信接口不被频繁访问,会限制用户每分钟获取验证码的频率,例如一分钟不能超过5次
伪代码:1
2
3
4
5
6
7
8
9phoneNum = "138xxxxxxxx";
key = "shortMsg:limit:" + phoneNum;
// SET key value EX 60 NX
isExists = redis.set(key,1,"EX 60","NX");
if(isExists != null || redis.incr(key) <=5){
// 通过
}else{
// 限速
}
在一秒钟之内访问超过n次也可以采用类似的思路
6. 消息队列
列表核心命令
| 类型 | 命令 | 说明 | 备注 |
|---|---|---|---|
| 列表 | lpush moss haha | 从左边插入元素 | |
| 列表 | rpush moss haha | 从右边插入元素 | |
| 列表 | lpop moss haha | 从左边弹出元素 | |
| 列表 | rpop moss haha | 从右边弹出元素 | |
| 列表 | blpop moss haha 3 | 从左边阻塞弹出元素 | 阻塞时间以秒为单位 |
| 列表 | brpop moss haha 0 | 从右边阻塞弹出元素 | 阻塞时间以秒为单位,0为一直等待 |
| 列表 | lrange moss 0 9 | 获取指定范围内的元素列表 | |
| 列表 | ltrim moss 1 3 | 按照索引范围修建列表,该操作只会保留moss中第2到第4个元素 |
原理:使用lpush+brpop的组合命令可以实现阻塞队列,生产者使用lpush从列表左侧插入元素,消费者使用brpop抢占尾部元素
- lpush+lpop=Stack(栈)
- lpush+rpop=Queue(队列)
- lpush+ltrim=Capped Collection(有限集合)
- lpush+brpop=Message Queue(消息队列)
7. 文章列表
场景:每个用户都有属于自己的文章列表,现需分页展示文章列表
1 | //首先将文章信息进行保存 |
8. 用户标签
场景:获取用户的标签,得到共同喜好的标签,定向推送
集合核心命令
| 类型 | 命令 | 说明 | 备注 |
|---|---|---|---|
| 集合 | sadd moss haha | 添加元素 | |
| 集合 | srandmember moss 2 | 随机从集合中返回2个元素 | |
| 集合 | spop moss | 从集合中随机弹出元素 | |
| 集合 | sinter moss moss1 | 获取moss和moss1的交集 |
1 | //增加用户相关标签 |
- sadd=Tagging(标签)
- spop/srandmember=Random item(生成随机数,比如抽奖)
- sadd+sinter=Social Graph(社交需求)
9. 排行榜系统
有序列表核心命令:
| 类型 | 命令 | 说明 | 备注 |
|---|---|---|---|
| 有序列表 | zadd moss 88 shentu | 添加成员,分数可以重复,但member不能重复 | 有序集合相比集合提供了排序字段,但提高了时间复杂度,zadd时间复杂度为O(log(n)),sadd的时间复杂度为O(1) |
| 有序列表 | zscore moss shentu | 计算某个成员的分数,这里可以的到分数88分 | |
| 有序列表 | zrank moss member | 计算某个成员的排名,排名从低到高 | |
| 有序列表 | zrevrank moss member | 计算某个成员的排名,排名从高到低 | |
| 有序列表 | zrange moss 0 2 [withscores] | 按照排名范围输出(低到高),若加上withscores关键词则同时会返回成员的分数 | |
| 有序列表 | zrevrange moss 0 2 [withscores] | 按照排名范围输出(高到低),若加上withscores关键词则同时会返回成员的分数 | |
| 有序列表 | zrangebyscore moss 221 200 withscores | 按照分数从低到高输出 | |
| 有序列表 | zrevrangebyscore moss (200 +inf withscores | 按照分数从高到低输出 | 支持开区间、闭区间,+inf和-inf表示无限大与无限小 |
1 | // 初始化用户视频 |
X. 分布式锁
如果有多个客户端同时执行setnx key value,
根据setnx的特性只有一个客户端能设置成功,setnx可以作为分布式锁的一种
(三)Redis其他知识
| 命令 | 说明 | 备注 |
|---|---|---|
| rename key newkey | 重命名键 | 在命名之前如果newkey已经存在,那么将会覆盖newkey的值 |
| renamenx key newkey | 重命名键 | 确保只有newkey不存在才能够重命名 |
| expire key seconds | 在x秒之后过期 | seconds设置为负值时,key会马上被删除,同del,※在set时会去掉过期时间 |
| expireat key timestamp | 在xxxxxxx的时间戳后过期 | |
| persist key | 可清除过期时间 | |
| keys pattern | 遍历键 | pattern为表达式,*代表任意字符,?匹配一个字符,[j,r]表示匹配j或者r,[1-10]表示匹配1-10的任意数字,\x用来做转义,例如:keys * 则表示列出全部的key。※ 该命令易引起redis的堵塞 |
| *scan cursor [match pattern] [count number] | 通过游标遍历redis中所有键 | 遍历效果可能会碰到如下问题:新增的键可能没有遍历到,遍历出了重复的键等情况,也就是说scan并不能保证完整的遍历出来所有的键 |
(四)Redis配置
redis.conf中bind 0.0.0.0是什么意思
0.0.0.0 在服务器的环境中,指的就是服务器上所有的ipv4地址,如果redis的机器上有2个ip: 192.168.30.10 和 10.0.2.15,redis 在配置中,如果配置监听在0.0.0.0这个地址上,那么,通过这2个ip地址都是能够连接到这个redis服务的。另外,访问127.0.0.1 也是能够访问到redis服务的。
如果绑定到192.168.30.10,那么只有通过这个ip地址才可以访问。访问127.0.0.1都是访问不到的。